
[Data Science] 정규화 vs 표준화
개요

정규화와 표준화는 머신러닝 알고리즘을 학습시키는데 있어 기본적이면서 중요한 역할을 한다. 이것을 간과하면 성능에 치명적인 영향을 끼치게 된다.
정규화와 표준화란 간단히 말해서 머신러닝 알고리즘을 학습시키는데 있어 사용되는 특성(feature)들이 모두 비슷한 영향력을 행사하도록 값을 변환해주는 기술입니다.
정규화 & 표준화 왜 필요할까?
머신러닝은 많은 양의 데이터를 통해 머신(기계)을 학습시키는 것을 말합니다. 보통 예측 or 분류하고자 하는 것과 관련되어 있는 여러 가지 특성을 가지고 머신러닝 알고리즘을 훈련시킵니다.

예를 들어, 부동산의 가격을 예측하기 위해 어떤 머신러닝 알고리즘을 훈련시킨다고 해보겠습니다. 그렇다면 부동산 가격과 연관이 있을거 같은 특성들을 도출합니다. 아마 지하철과의 거리, 집의 평수 등이 관련 있는 특성들일 것입니다.
여기서 문제는 평, km 등 여러 특성들의 단위가 다르고 값의 범위도 꽤 차이가 있다는 것입니다.
문제
-
단위가 다르면 비교할 수 없다. ex) 내가 186cm이지만 너는 90kg니깐 너가 더 돼지야. -> 말도 안됨.
-
값의 범위가 다르면 비교할 수 없다. ex) 너는 100점 만점에 80점, 나는 10000점 만점에 90점이니깐 내가 더 공부 잘하네 -> 말도 안됨.
따라서 이러한 문제를 해결하기 위해 특성들의 단위를 값의 범위를 비슷하게 만들어줄 필요가 있습니다. 그것이 바로 정규화와 표준화가 하는 일입니다. 그리고 이러한 정규화와 표준화가 하는 일이 특성 스케일링(feature scaling), 데이터 스케일링(data scaling)이라고 합니다.
정규화와 표준화의 차이는 무엇인가요?
1. 정규화(Normalization)
정규화는 특성의 값을 0~1사이의 값으로 옮긴다.
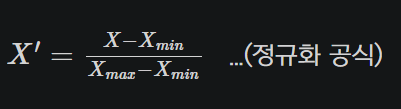
이 공식을 사용해 정규화를 하게 되면 한 특성 내에 가장 큰 값은 1로 가장 작은 값은 0으로 치환되고 그 사이에 나머지 값들도 0~1 사이의 값들로 치환된다.
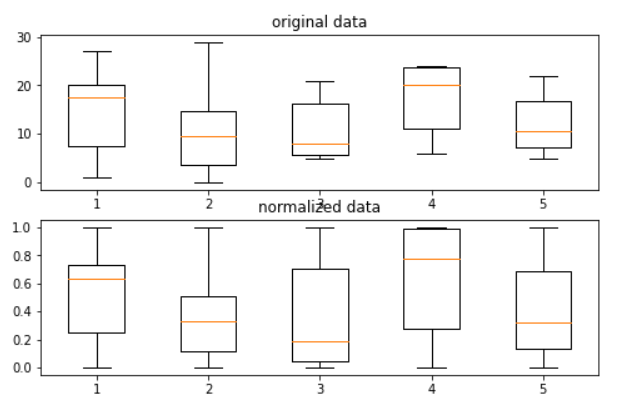
정규화하는 것을 코드로 살펴보자.
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
data=np.random.randint(30 , size=(6,5))
normalization = MinMaxScaler().fit_transform(data)
fig = plt.figure(figsize=(8, 5))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.set_title('original data');
ax1.boxplot(data);
ax2.set_title('normalized data');
ax2.boxplot(normalization);
2. 표준화(Standardization)
표준화는 한 특성 내의 값들의 분포를 정규분포를 따르게끔 만들어 주는 것입니다. 아래의 공식에서 한 특성의 값을 그 특성의 평균으로 뺀 값을 표준편차로 나눠 줌으로써 정규분포, 즉 종 모양의 분포를 따르게끔 만들어주는 것입니다.(정규분포의 표준화)

이를 통해 평균은 0이 되고 표준편차는 1이된 정규분포를 따르는 특성으로 바뀔 수 있습니다.
코드로 표준화를 살펴보자
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
data=np.random.randint(30 , size=(6,5))
standardization = StandardScaler().fit_transform(data)
fig = plt.figure(figsize=(8, 5))
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
ax1.set_title('original data');
ax1.boxplot(data);
ax2.set_title('standardized data');
ax2.boxplot(standardization);
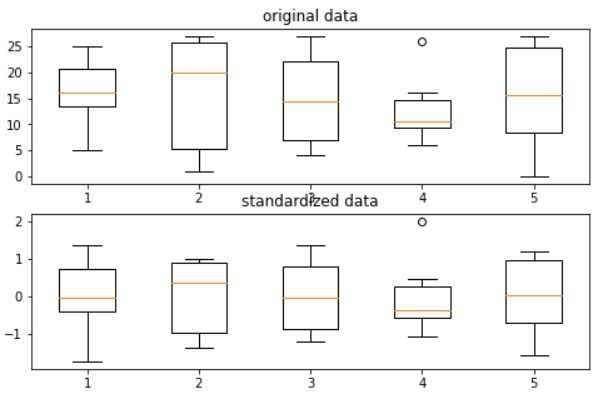
근데, 표준화를 시켰는데 모든 데이터의 평균이 왜 0이 아니지?
정규화와 표준화 중 어떤 것이 더 나은가?
무엇이 더 낫다라고 명확하게 말할 수는 없습니다. 다만 머신러닝 알고리즘을 학습시킬 때 정규화와 표준화를 하고 안하고의 차이는 엄청나다는 것이 중요합니다.
특정한 경우에는 표준화를 했을 때 성능이 더 좋고, 그 반대의 경우에는 정규화를 한 것이 성능이 더 좋을 수 있기 때문에 정규화와 표준화를 모두 해보고 성능이 더 좋은 것을 선택해야 합니다.


