
[Data Science] Feature Engineering

1. 개요
데이터 사이언티스트 또는 데이터 직군에서 일하는 사람들이 가장 많이 소비하는 시간은 Data cleaning하는 시간이다.
그 이유는 실세계의 데이터는 엄청 엉망진창이고 복잡하기 때문이다. 만약 데이터가 너무 엉망진창하고 복잡하다면 우리가 훗날 머신러닝 모델에서 사용하기가 어렵다. 그래서 우리가 사용하고자 하는 데이터로 수정, 가공해줘야 한다.
데이터 분석의 중요한 부분인 Feature Engineer은 도메인 지식과 창의성을 바탕으로, 데이터 셋에 존재하는 Feature들을 재조합하여 새로운 Feature를 만드는 것이다.
ps)Feature Engineering이 Data Cleaning을 돕는다.
2. Feature Engineering의 여러 가지 방법 중 3가지
Feature Engineering은 수학, 통계, 그리고 도메인 지식을 사용해서 raw data로부터 유용한 특징을 추출하는 과정이다. Data Cleaning을 하는 과정에 포함되는 프로세스라고 이해하면 좋을 것 같다.
아래의 3가지 과정은 manual이고, 요즘에는 발전된 신경망을 통해 자동으로 의미있는 특징을 추출할 수 있다.
2-1. Outlier detection
- Domain Knowledge을 활용
- Visualization 활용
- Math/Statistics: Two standard deviation 활용
위의 3가지 방법을 통해 이상치를 감지할 수 있다.
2-2. Handling missing values
- 결측값 삭제
- 나머지 실값의 평균으로 대체
2-3. One Hot Encoding(category -> numeric)
범주형 데이터를 이용해서 머신러닝 모델을 트레이닝 시킬 수 없다. 머신모닝 모델은 범주형 데이터를 이해하지 못하기 때문이다. 그래서 범주형 데이터를 수치형 데이터로 바꿔준다.
3. Dataframe?
데이터 프레임은 테이블 형태의 데이터다 정도로만 이해해도 충분합니다.
일반적으로 하나의 행에는 하나의 데이터 혹은 관측치, 하나의 열에는 하나의 feature를 기반으로 저장합니다.
아래의 데이터프레임을 tidy data라고 부릅니다. 테이터 분석에 사용하는 데이터는 다른 라이브러리들과의 호환성을 위해 tidy data의 형태로 변형해주어야 합니다.
3-1. 데이터프레임 살펴보기
kt&g 기업의 일부 재무정보 데이터의 데이터프레임을 살펴보겠습니다. 이를 통해 feature engineering의 사용에 대해서도 함께 살펴보겠습니다.
import pandas as pd
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/kt%26g/kt%26g.csv')
df.dtypes
#output:
분기 object
매출액 object
영업이익 object
영업이익(발표기준) object
세전계속사업이익 object
당기순이익 object
당기순이익(지배) object
당기순이익(비지배) int64
자산총계 object
부채총계 object
자본총계 object
자본총계(지배) object
자본총계(비지배) float64
자본금 object
영업활동현금흐름 object
투자활동현금흐름 object
재무활동현금흐름 object
영업이익률 float64
순이익률 float64
ROE(%) float64
ROA(%) float64
부채비율 float64
자본유보율 float64
EPS(원) object
PER(배) float64
dtype: object
데이터는 모두 숫자형 데이터이지만, 그 형태가 object, int64, float64로 다양한 것을 확인할 수 있습니다.
일부 column에 해당하는 데이터를 살펴보겠습니다.
자본총계(비지배) 컬럼을 보면 NaN이라는 값이 있는 것을 확인할 수 있습니다.
NaN(Not A Number)은 pandas에서 결측치를 표현하는 방법입니다. 이러한 NaN은 프로그래밍 특성상 float의 type을 갖게 되고 해당 컬럼의 나머지 수치인 562,566은 NaN의 영향으로 float의 type을 갖게 되는 것입니다.
df['자본총계(비지배)']
#output:
0 NaN
1 NaN
2 NaN
3 562.0
4 566.0
Name: 자본총계(비지배), dtype: float64
특정 열을 이용해 새로운 feature를 만들어보자! -> feature engineering
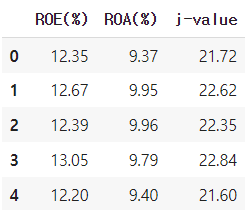
기존의 feature를 사용해서 새로운 feature인 j-value를 만들어보겠습니다.
df['j-value'] = df['ROE(%)'] + df['ROA(%)']
df.loc[:,['ROE(%)','ROA(%)','j-value']]
데이터프레임의 수치형 데이터의 type이 object -> numeric으로 변환해보자!
다음의 2단계를 거쳐야 한다.
- 해당 데이터의 숫자가 아닌 부분을 제거
- 해당 단계를 수행하기 위해 string 클래스의 replace 메소드를 사용하면 된다.
change_string = '20,333'
change_string.replace(',','') #output: '20333'
- 문자를 숫자로 형변환
int(change_string.replace(',','')) #output: 20333
이러한 과정을 데이터프레임에 적용하기 위해서는 해당 과정을 함수로 만든 뒤 apply메소드를 사용하거나, pandas에 구현되어 있는 특정 메소드를 사용하면 된다.
apply 메소드 사용
#먼저, object -> numeric으로 바꾸는 함수 생성
def toInt(string):
return int(string.replace(',',''))
#apply 메소드로 수치형 데이터로 바꾸기 전
df['자산총계']
#output:
0 108,464
1 106,314
2 107,121
3 108,594
4 110,282
Name: 자산총계, dtype: object
#apply 메소드 수치형 데이터로 바꾼 후
df['자산총계'].apply(toInt)
#output:
0 108464
1 106314
2 107121
3 108594
4 110282
Name: 자산총계, dtype: int64
#또 다른 방법, 결과는 apply를 적용해서 나오는 결과와 동일하다.
df['자산총계'].str.replace(',','').apply(int)
#데이터프레임 자체에는 적용될 수 없다. 아래와 같은 코드 실행 시 오류가 발생한다.
df.loc[:,['자산총계','부채총계']].str.replace(',','').apply(int)
pandas에 내장되어 있는 함수 사용


