
[Data Science] 통계 개념 정리

학습 목표 _ 이건 꼭 알고가자!
- Estimation / Sampling의 목적과 방법에 대해서 이해한다.
- 가설검정에 대해서 이해한다.
- T-test의 목적과 사용예시를 설명할 수 있다.
- 이외에도 모르는 게 있다면 이번에 확실히 알고 넘어가자!
1. 확률을 왜 사용할까?
세상이 복잡해질수록 불확실성은 높아지는데 이러한 불확실성 가운데에서도 올바른 판단을 하기 확률에 기반한 사고가 필요하다.
2. 경험주의?
감각의 경험을 통해 얻은 증거들로부터 비롯된 지식을 강조하는 이론이다. 여기서 감각 경험이란 결국 현실 데이터를 지칭한다.
PS. 경험주의자 입장에서는 100% 확신하는 지식은 없지만 통계학을 통해서 어떤 지식이 상대적으로 더 확실한 것인지에 대해 합리적인 진술을 할 수 있게 된다.
3. 가설이란?
테스트가 가능한 아이디어 혹은 검정하고 싶은 아이디어 혹은 우리가 알고 싶어하는 모집단의 모수(예: 평균, 분산, 등)에 대한 잠정적인 주장이다.
4. 기술 통계(Descriptive Statistics란?
수집한 데이터를 요약, 묘사 설명하는 기법 혹은 count, mean, standard 등의 수치화로 데이터의 요약, 묘사가 가능하다.
- 기술 통계치의 시각화
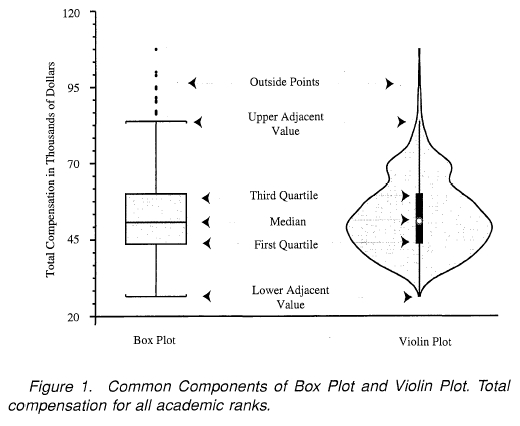
- boxplot

- violin plot
- boxplot을 개량화한 시각화 방법이다. 그림에서 보는 것처럼 데이터의 분포를 쉽게 확인할 수 있다.
5. 기술 통계 기법의 종류 2가지
- 데이터의 집중화 경향에 대한 기법
우리가 수집한 데이터를 대표하는 값이 무엇인지? 또는 어떤 값에 집중되어 있는지 다루는 기법
ex) 평균(mean), 중앙값(median), 최빈값(mode)
- 데이터가 어떻게 퍼져 있는지 확인하는 기법
이를 _분산도_ 라고 하는데 말 그대로 데이터가 전반적으로 어떻게 분포되어 있는지 설명하는 방법이다.
ex) 표준편차(standard deviation), 사분위(quartile)
6. 추리 통계(Inferential Statistics)?
수집한 데이터를 기반으로 어떠한 것을 추리하고 예측하는데 사용하는 기법
7. 아래의 사진은 추리 통계의 과정을 보여주고 있다. 해당 그림에서 전체 데이터 중 SAMPLE값을 추출하는 이유가 무엇인가?

예를 들어, 국내 연령대별 키 평균을 구하고 싶다고 하자. 모든 연령대의 사람들의 키 데이터를 수집하고 평균을 구한다면 그 결과는 어떤 것보다도 정확할 것이다. 하지만, 우리는 국내의 모든 사람의 데이터를 수집할 수 없다. 한계가 있다. 따라서 모집단에서 표본을 추출하여 우리가 얻고자 하는 값을 구하고 그 값을 토대로 예측 및 추론을 하는 것이다. 이러한 이유 때문에 전체 데이터 중에서 sample 값을 추출한다.
8. sample하는 방법이 여러가지가 존재한다. 그 중 대표적인 4가지?
1. Simple random sampling
모집단에서 sampling을 무작위로 하는 방법이다.

2. systematic sampling
모집단에서 sampling을 할 때 규칙을 가지고 추출하는 방법이다. 1,6,9,11 번째.. 이렇게 말이다!

3. Stratified random sampling
모집단을 미리 여러 그룹으로 나누고, 그 그룹별로 무작위로 추출하는 방법이다. 쉽게 말해, 여론 조사를 위해 나이대별로 그룹을 나누고, 해당 그룹에서 랜덤으로 추출하는 것이다.
4. Cluster sampling
모집단을 미리 여러 그룹으로 나누고, 이후 특정 그룹을 무작위로 선택하는 방법이다.

9. 가설 검정이란? 그리고 가설 검정을 하는 이유?
이 대답에 앞서 모수에 대한 개념부터 정립하는 것이 중요하다. 기본적으로 모수란, 수학과 통계학에서 어떠한 시스템이나 함수의 특정한 성질을 나타내는 변수를 말한다. 예를 들어, '한국 여성의 평균키는 168CM이다.'라고 했을 때 '평균 신장'이 모수에 해당한다.
가설 검정은 또 다른 말로 통계적 가설 검정이라고 하는데 이는 모집단의 특성에 대한 통계적 가설을 표본 추출을 통해 검토하는 통계적인 추론이다. 여기서 모집단의 특성이라 하면 위의 모수라고 하 수 있고 예로는 '평균신장'을 들 수 있겠다.
가설 검정을 하는 이유는 새로운 가설에 대한 증거를 뒷받침하기 위해서 하는 것이다. 기존의 가설이 틀렸다는 것을 새로운 가설로 입증함으로써 새로운 가설에 대한 증거를 찾는 것을 말한다.
10. 귀무가설(Null Hypothesis), 대립가설(Alternative hypothesis)?
귀무가설이란, 기본적으로 모집단의 특성에 대해 옳다고 제안하는 잠정적인 주장이다. 대립가설은 귀무가설이 만일 거짓이라면 대안적으로 참이 되는 가설을 말한다. 귀무가설의 또 다른 정의는 처음부터 버릴 것을 예상하는 가설을 말한다.
11. 표본평균의 표준오차?
왜 표본의 크기가 커지면, 표준 오차가 줄어들까? 그 이유는 모집단에서 커다란 표본을 뽑을 수록 모집단과 가까워지고 이에 따라 오차가 줄어들게 된다. 그래서 표본의 크기가 커지면 커질수록 오차는 줄어들게 된다.
12. P VALUE
어떤 사건이 우연히 발생할 확률을 말한다. 이러한 P 값이 0.05보다 작다면 우연히 발생할 확률이 5%보다 낮다는 것을 의미한다. 즉, 우연히 발생한 것이 아닌 무언가 이유가 있을 것으로 판단되는 것입니다. 따라서 이러한 경우에 _유의하다_ 라고 표현하는 것입니다.
13. 귀류법?
수학과 논리학의 증명법 중 하나. 어떤 명제가 거짓이라고 가정한 후 모순을 이끌어내 그 가정이 거짓임을 증명, 처음의 명제가 참임을 증명하는 방법이다.
주로 가설 검정에서 대립 가설을 증명하기 위해 귀무가설이 틀렸다는 것을 증명할 때 사용한다.
14. Z-score?
원수치인 x가 평균에서 얼마나 떨어져 있는지를 나타낸다.
P(0<Z<z)의 의미는 표준 정규 분포에서 0부터 z라는 값까지에 속할 확률을 말한다.
z-scores have a mean of 0 and a standard deviation of 1?
z-score는 평균이 0이고 표준편차가 1이다.
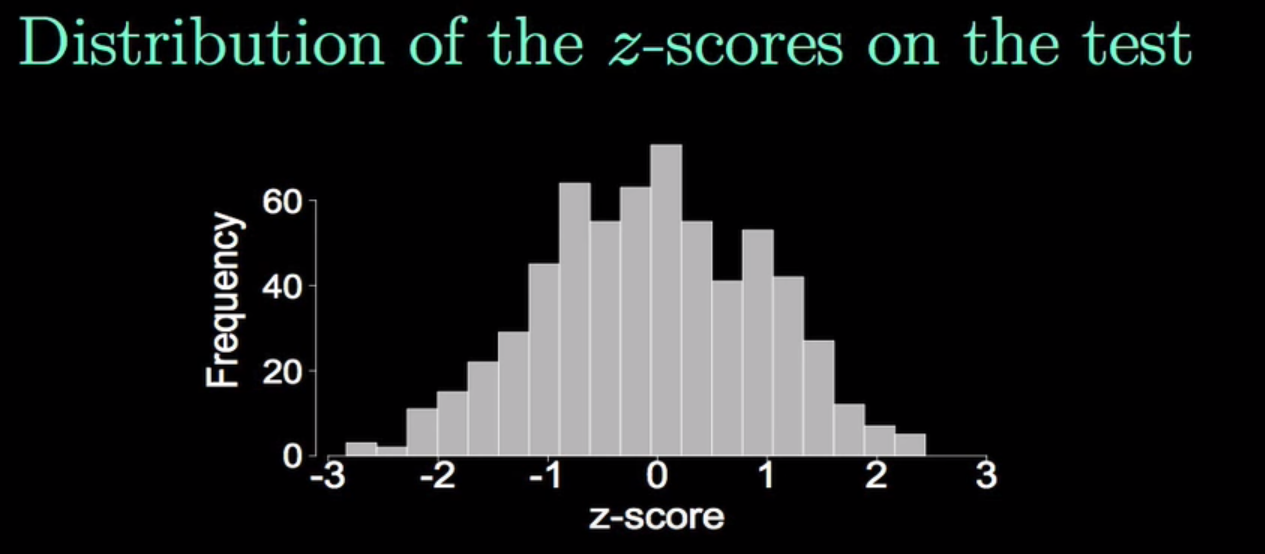
이 값이 의미하는 바는 평균으로부터 z standard devation만큼 위에 있다. 퍼져있는 위치?를 나타내느 것 같다.
모든 관측값은 z-score를 가지고 있고 구할 수 있다.
결국, z-score이라는 것은 _상대적 위치를 설명하는 척도_ 라고 할 수 있다.
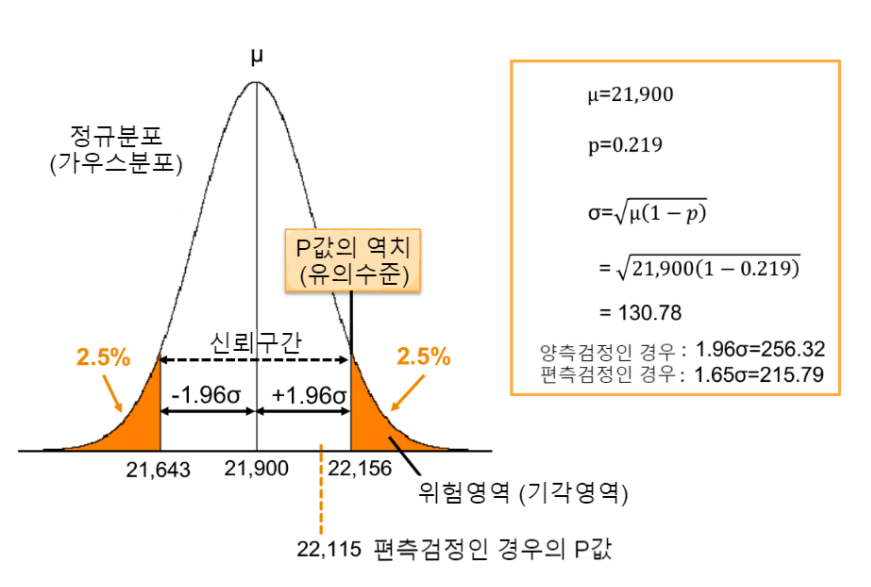
15. 유의수준?
아래 그림에서 P 값이 역치보다 작다면 위험영역 안에 해당이 되고 이러한 경우 해당 가설이 더 이상 우연이라 할 수 없고, 뭔가 의미가 있다는 의미이므로 유의수준이라고 할 수 있게 된다.
아래 그림에서 유의수준은 21,643과 22,156이라고 볼 수 있다.
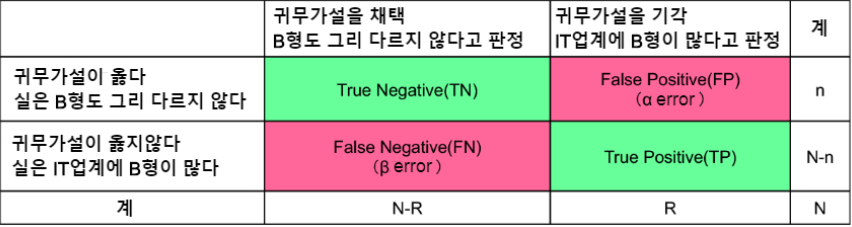
16. False Positive & False Negative?
False Positive(거짓 양성): 통계상 실제로는 음성인데 검사 결과는 양성이라고 나오는 것이다.
예를 들어, 메일을 검사해 스팸인지 아닌지 구분하는 프로그램이 있다고 하자. 해당 메일이 스팸이 아니지만 프로그램 검사 결과 스팸 메일이라고 판정한다면 이것을 거짓 양성 이라고 한다.
False Negative(거짓 음성): 실제로는 양성인데 검사 결과는 음성이라고 나오는 것이다.
예를 들어, 어떤 메일이 스팸 메일인데 프로그램 검사 결과 스팸 메일이 아니라고 판정한다면 이것을 거짓 음성 이라고 한다.
17. P-value?
어떤 사건이 우연히 발생할 확률!
18. 가설 검정
모집단에 대한 어떤 가설을 설정하고 표본 추출을 통해 해당 가설을 채택여부를 결정하는 방법
19. Empirical rule(경험적인 규칙)?
정규분포를 기반으로 한 규칙이다.
1. 약 68%의 값들이 평균에서 -1~1 표준편차 범위 안에 존재한다.
2. 약 95%의 값들이 평균에서 -2~2 표준편차 범위 안에 존재한다.
3. 약 99.7%의 값(거의 모든 값)들이 평균에서 -3~3 표준편차 범위 안에 존재한다.
ps) -1~1,-2~2,-3~3 은 모두 z-score이다.
20. 정규분포 vs 표준정규분포?
정규분포
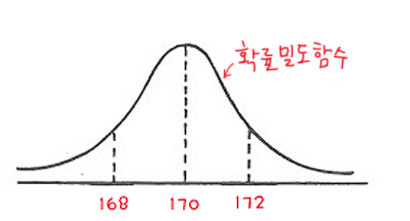
이러한 정규분포를 통해 어떤 범위에 해당하는 비율을 알 수 있다.
아래 그림을 보면, 키가 170~172 사이의 넓이를 나타내고 있고 해당 수치가 0.4가 나왔다면 전체 중에 40%가 170~172사이에 해당한다고 해석할 수 있습니다.
결과적으로 해당 정규 분포의 전체 넓이는 총 확률 값 1과 동일하다고 생각하시면 됩니다.
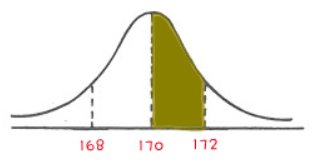
표준정규분포
정규분포를 사용하는 이유는 해당 범위에 대한 비율을 알기 위해서 입니다. (정규분포에서 넓이를 통해 해당 범위에 대한 비율을 알 수 있습니다.) 하지만, 정규분포는 조사할 때마다 달라지기 때문에 표준적으로 사용할 수 있는 정규분포의 필요성을 느꼈고 이를 해결하기 위해 나온 것이 표준정규분포 입니다.
표준정규분포의 x축의 값은 z_score로 표현이 되는데 이것은 평균값에서 표준편차의 몇배만큼 떨어져 있는 숫자인가?를 의미합니다.
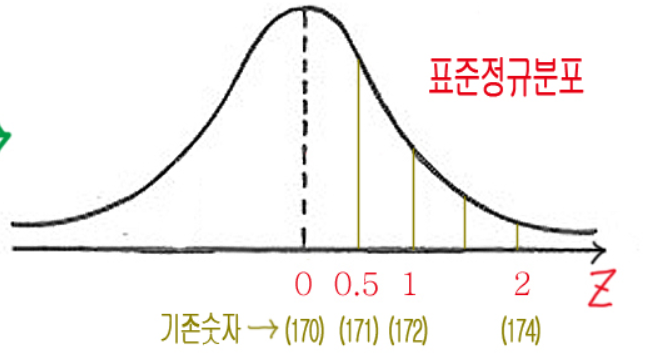
기존 정규분포의 x축의 값을 평균에서 표준편차의 몇배만큼 떨어져 있는지로 바꿨다고 보시면 됩니다.
결론은 우리가 알고 싶은 범위의 비율에 대해 알기 위해 사용하는 정규분포는 조사를 할 때마다 값이 달라지기 때문에 표준으로 사용할 수 있는 정규분포의 필요성을 느꼈습니다. 이러한 필요를 충족시키기 위해 표준정규분포가 나왔고 해당 범위를 z 값으로 바꿔주고 바뀐 z값의 범위에 따라 사전에 정의되어 있는 구간별 확률값을 통해 우리가 알고 싶어하는 비율 수치를 알 수 있게 되는 것입니다.
21. 표준편차?
표준편차라는 것은 정규분포의 모양을 알려주는 값이라고 생각하면 됩니다. 하지만 더 중요한 것은 표준편차를 사용해서 표준정규분포라는 것을 만들 수 있습니다.
22. t 분포?
사전 정보
우리가 알고 있는 표준편차를 이용하여 표준정규분포를 만들기 위해 z-score를 구해야 한다. 하지만, 거의 대부분의 경우 우리는 표준편차의 값을 알지 못한다. 그래서 대체 수치로 모집단에서 추출한 표본의 표준편차를 사용한다. 여기서 중요한 것은 기존의 모집단의 표준편차는 일정한 값이지만 표본의 표준편차는 통계량이다. 즉 표본에 따라 값이 다르다. 그래서 표본의 표준편차를 통해 z-score를 구하고 표준정규분포를 구하려고 했지만 표본마다 다른 값을 가지는 표준편차의 사용으로 인해 더 이상 표준정규분포를 가질 수 없게 된다.(만들 수 없게 된다.)
t 분포는 양측의 꼬리 무분이 표준정규분포에 비해 분포가 많고 평균 부분의 값이 더 낮다.
t 분포는 자유도에 영향을 많이 받는데, 자유도가 증가함에 따라 점점 더 표준 정규 분포의 형태와 유사하게 된다.
그래서 표본의 크기가 커질 수록 자유도가 증가하게 되고 이에 따라 t 분포는 표준정규분포와 유사하게 바뀌고 결국 표준오차가 감소하게 된다. 왜냐하면, 표준오차는 표본 통계량의 표준 편차이기 때문이다.
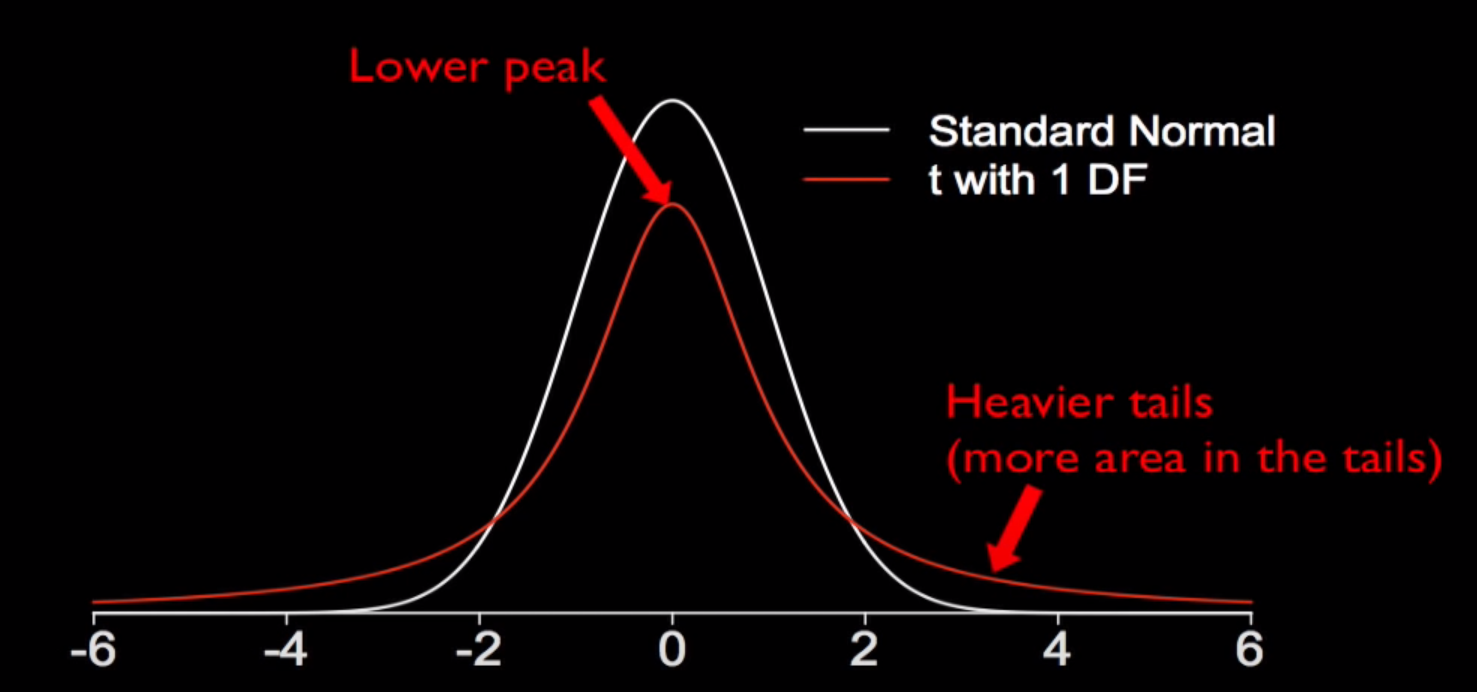
모집단의 표준편차를 알 수 없어 표본의 표준편차를 사용한 t_score, 이러한 t 값으로 인해 이제 t 분포를 가진다.
$ t = \frac{x(관측값)-m(평균값)}{표본의 표준편차} $
기존의 우리가 구하려고 했던 z_score
$ z = \frac{x(관측값)-m(평균값)}{모집단의 표준편차} $
23. 95% confidence intervals
95% confidence intervals에서 z의 값은 1.96인데 1.96가 동일한 t 값을 가지기 위해서 자유도는 무한의 값을 가져야 한다. 따라서, 종종 표본의 크기가 30이상이면 그*냥 표준정규분포를 사용해라라는 말이 있는데 표본의 크기가 30일 때 t 값은 2.042이다. 이 값도 1.96에 비해 꽤 크다고 볼 수 있다. 따라서 우리가 정규분포로부터 표본을 추출해서 해달 표본의 표준편차를 사용할 것이라면 t 분포로부터의 값을 사용해라! 표준정규분포로부터가 아닌!


