[Data Science] Data Manipulation

개요
- pandas를 통해 데이터를 concat/merge 할 수 있다.
- tidy 데이터에 대한 개념을 이해한다.
- melt와 pivot/pivot_table 함수를 사용하여 wide와 tidy 형태의 데이터를 서로 변환할 수 있다.
1. data 합치기
우리가 효과적인 데이터 분석을 위해서는 데이터를 합치는 것도 필요하다. 그 중에서도 대표적으로 concat & merge에 대해 알아보겠다.
1-1. Concat
concat은 ‘더한다’ 혹은 ‘붙인다’라는 의미로 생각하면 이해가 편리하다. 예를 들어 두 개의 문자열을 ‘+’을 통해 더할 수 있습니다.
'hi' + 'hello' #output: hihello
+ 연산자를 사용하지 않고도 파이썬 내장함수를 통해 문자열을 더할 수 있습니다.
#join
'_'.join(['a','b']) #output: 'a_b'
더하는 것뿐만 문자열을 쪼개는 것도 파이썬의 split() 내장함수를 이용하면 가능합니다.
split의 parameter로 쪼개는 기준이 되는 인자를 넣어 줍니다.
'hi my name is jungin'.split(' ')
#output: ['hi', 'my', 'name', 'is', 'jungin']
이제 본격적으로 데이터 프레임내의 열 또는 행을 합치는 것을 살펴보겠습니다.
데이터프레임을 더할 때는 일반적으로 열 또는 행의 이름이나 인덱스가 일치해야 합니다. 그렇지 않은 경우 비어있는 부분에 대해서는 NaN 값으로 채워지게 됩니다.
import pandas as pd
x = pd.DataFrame([[10,20],[4,8]],index=['A','B'],columns=['X','Y'])
y = pd.DataFrame([[30,10],[5,4]],index=['A','C'],columns=['X','Z'])
pd.concat([x,y],axis=1)
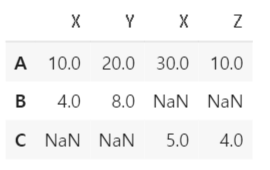
위의 그림을 보면 x 데이터프레임에는 C라는 index가 없기 때문에 해당 feature에 NaN이 들어갔고 y 데이터프레임에는 B라는 인덱스가 없기 때문에 해당 feature에 NaN 값이 들어간 것을 확인할 수 있다.
1-2. Merge
merge는 concat과 달리 공통된 부분을 기반으로 합치기가 주요 용도이다.
Merge를 설명하기 위해 사용할 데이터프레임은 아래와 같다.
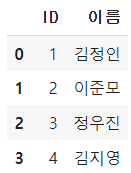
import pandas as pd
A = pd.DataFrame({'ID' : [1, 2, 3, 4],
'이름' : ['김정인', '이준모', '정우진','김지영']})
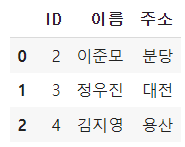
B = pd.DataFrame({'ID' : [2, 3, 4, 5],
'주소' : ['분당', '대전', '용산', '분당']})

df.merge(“붙일 내용”, how = “(방법)”, on =”(기준 feature)”)
on 옵션
on = None이 default 값이고 on = ‘지정된 값’에 따라 동일한 이름의 column(key column)을 기준으로 합쳐진다.
how = ‘inner’ 옵션 사용
how = inner 옵션은 df.merge()의 default 옵션이다. 결합하고자 하는 데이터프레임내에 모두 값이 있는 행만을 병합한다. 교집합과 유사하다.
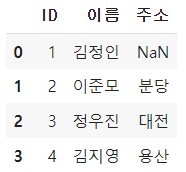
pd.merge(A,B,how='inner',on='ID')
how = ‘outer’ 옵션 사용
결합하고자 하는 데이터프레임내에 하나라도 데이터가 있는 행들을 병합한다. 합집합과 유사하다.
pd.merge(A,B,how='outer',on='ID')
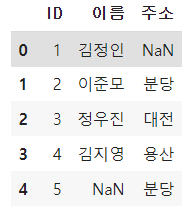
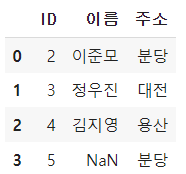
how = ‘left’
key 값을 기준으로 결합하고자 하는 데이터프레임의 왼쪽 값에 맞추어 결합되어 진다.
pd.merge(A,B,how='left',on='ID')
#on 옵션을 사용하지 않는다면 merge하는 값의 좌측이 기준이 된다.
how = ‘right’
key 값을 기준으로 결합하고자 하는 데이터프레임의 오른쪽 값에 맞추어 결합되어 진다.
pd.merge(A,B,how='left',on='ID')
데이터프레임의 특정 열 데이터를 numeric type으로 변환하기!
print('CAPEX type:',df3['CAPEX'].dtypes) #output: CAPEX type: object
df3['CAPEX'] = pd.to_numeric(df3['CAPEX'])
print('CAPEX type:',df3['CAPEX'].dtypes) #output: CAPEX type: int64
2. 데이터프레임 필터링!
2-1. 수치형 데이터 필터링
#필터링 조건! () 씌우는 것 주의하자.
condition = (A['ID']>3)
print(condition)
#output:
0 False
1 False
2 False
3 True
Name: ID, dtype: bool
[]안에 컨디션을 설정하는 것으로, 컨디션의 값이 True에 해당하는 부분을 뽑아낸다.
df_subset = A[condition]
df_subset
#output:

condition에 들어가는 조건을 하나만 설정할 필요는 없고 &(and) or |(or)를
이용하여 여러 조건을 동시에 설정할 수 있다.
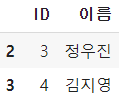
condition = ((A['ID']>2) & (A['ID']<=4))
or
condition 변수를 사용하지 않고 바로 적용할 수 있다.
A[((A['ID']>2) & (A['ID']<=4))]
2-2. 범주형 데이터 필터링
isin() or df[‘컬럼명’]==’데이터 명’
A[A['이름'].isin(['김지영'])]
A[A['이름']=='김지영']

groupby
df.groupby(‘컬럼명’).mean or sum ….
특정 컬럼을 기준으로 다른 수치형 데이터의 mean 값 또는 전체 합 값을 보여준다.
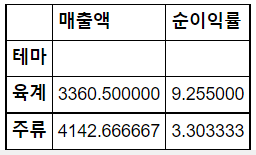
위의 그림은 테마를 기준으로 육계,주류의 매출액의 평균과 순이익률의 평균을 구했다.
Q. 종목코드에 8이 들어가는 것에 대해 필터링은 어떻게 진행할까?
df2 = pd.DataFrame(
{'종목' : ['000080', '000890', '005300', '027740', '035810', '136480', '136490'],
'종목명': ['하이트진로', '보해양조', '롯데칠성', '마니커', '이지홀딩스', '하림', '선진'],
'테마' : ['주류', '주류', '주류', '육계', '육계', '육계', '돼지고기']}
)
df2
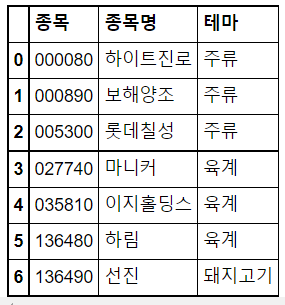
3. Tidy Data?
행에는 관측, 열에는 관측에서 표현되는 feature를 나타낸다. 아래의 widy data는 아직 정제되지 않은 야생의 데이터이다. 특정 라이브러리에서 데이터를 사용하기 위해서는 오른쪽의 tidy 데이터의 형태로 변환해주어야 한다. 예를 들어, 데이터 시각화에 사용되는 Seaborn 라이브러리 같은 경우 tidy data를 필요로 한다.
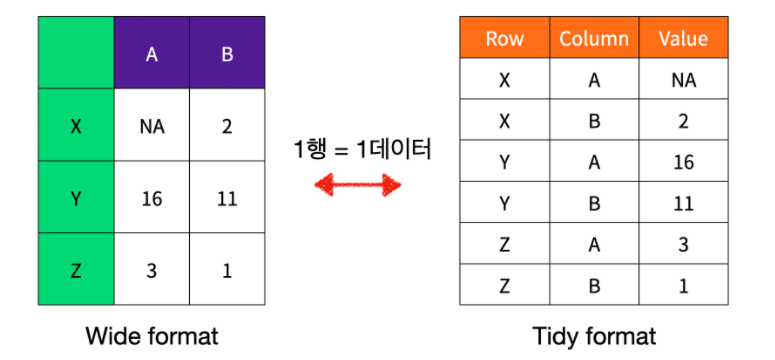
3-1. wide -> tidy
widy -> tidy 데이터로 바꾸는 것을 보여드리기 위해 아래의 데이터를 사용하겠습니다.
import pandas as pd
import numpy as np
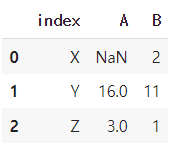
table1 = pd.DataFrame(
[[np.nan, 2],
[16, 11],
[3, 1]],
index=['X', 'Y', 'Z'],
columns=['A', 'B'])
table1 = table1.reset_index()
table1
본격적으로 melt 함수를 사용해보겠습니다. 해당 함수내에 id_vars 옵션은 기준이 되는 컬럼을, value_var에는 하나의 행에 하나의 관측이 보이게 하기 위해 나눠줘야 하는 컬럼을 넣어준다.
table1 = table1.melt(id_vars='index',value_vars=['A','B'])
table1
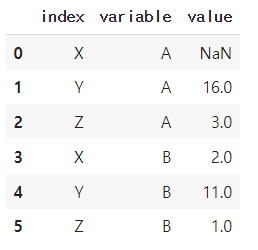
해당 데이터프레임의 컬럼명을 바꿔주자.
table1 = table1.rename(columns = {'index':'row',
'variable':'columns',
'value':'value'})
table1
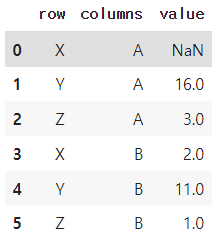
3-2. tidy -> wide
tidy -> wide 데이터로 바뀌기 위해서 pivot_table 함수를 사용할 것이다.
# 파라미터에 대한 설명
# index: unique identifier
# columns: "wide" 데이터에서 column별로 다르게 하고자 하는 값.
# values: 결과값이 들어가는 곳 (wide 데이터프레임의 내용에 들어갈 값)
wide = table1.pivot_table(index = 'row', columns = 'column', values = 'value')
wide
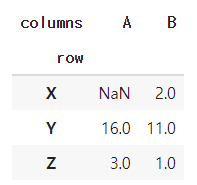
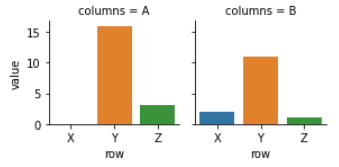
tidy 데이터의 목적 - seaborn
#Seaborn의 기능 중 한가지 예시입니다.
import seaborn as sns
sns.catplot(x = 'row', y = 'value'
, col = 'column', kind = 'bar'
, data = table1, height = 2);
#마지막에 ';'를 붙이면 '<seaborn.axisgrid.FacetGrid at 0x7fd7ac2b7350>' 이것이 출력되지 않는다.