[ML] Linear Regression
개요

선형회귀중에서도 단순선형회귀를 먼저 배우고 가겠습니다. 단순선형회귀는 1개의 feature, 1개의 target을 이용한 예측 모델을 말합니다.
선형 회귀 모델에 대한 이해하고 Scikit-learn을 이용해서 선형 회귀 모델을 만들어 보겠습니다. 특히, 종속 변수와 독립 변수, 회귀선을 이루고 있는 회귀 계수를 주의 깊게 살펴보겠습니다.
그리고 Least Square 방법이 무엇인지에 대해서도 알아보겠습니다.
이번 내용에서 사용할 데이터 셋
- 미국 시애틀 King County 지역에서 2014년 5월부터 ~ 2015년 5월까지 주택 판매 가격
import pandas as pd df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.\amazonaws.com/kc_house_data/kc_house_data.csv') df.head()
Linear Regression
1. 독립변수 & 종속변수
독립변수와 종속변수 간의 관계에 대해서 알아보겠습니다.
독립변수 & 종속변수의 다른 표현
- 독립변수
- 예측(Predictor)변수
- 설명(Explanotory)
- 특성(Feature)
- 종속변수
- 반응(Response)변수
- 레이블(Label)
- 타겟(Target)
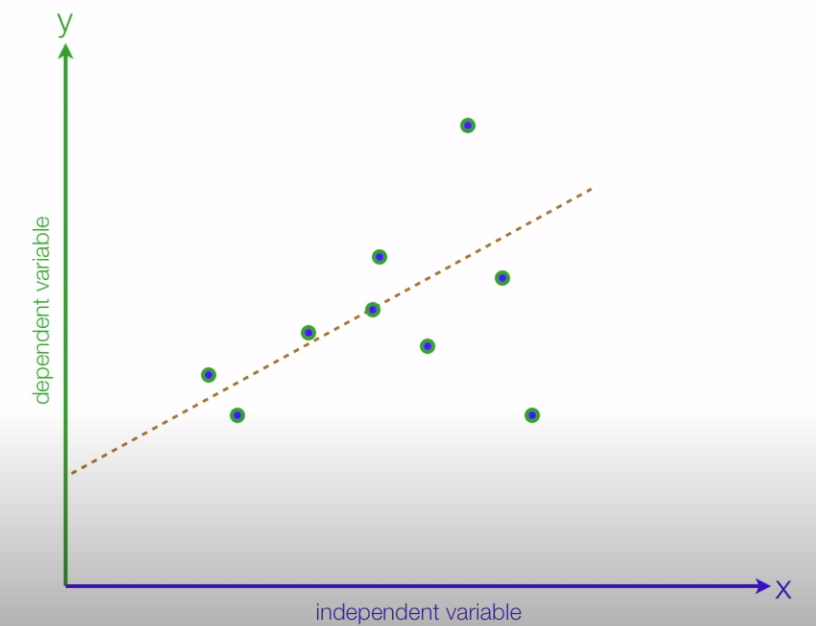
1-1. Positive Relationship & Negative Relationship
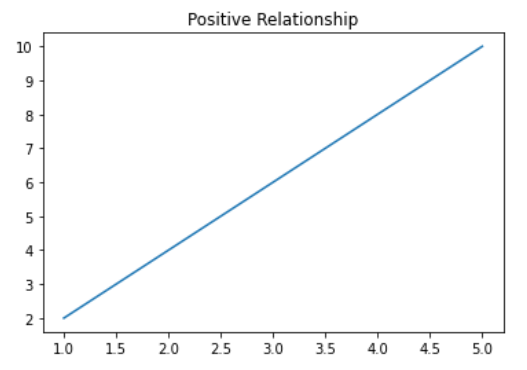
- Positive Relationshop
- 독립변수가 증가함에 따라 종속변수도 증가하는 관계를 뜻한다.
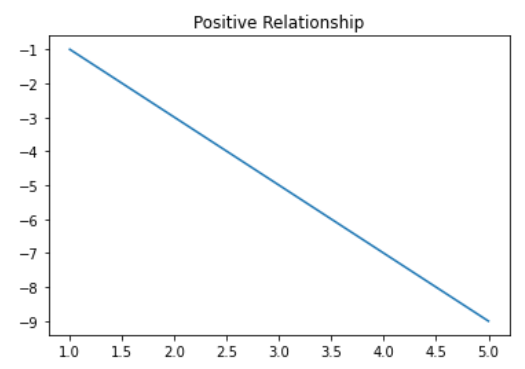
- Negative Relationshop
- 독립변수가 증가함에 따라 종속변수가 감소하는 관계를 뜻한다.
1-2. coefficient & intercept
회귀 직선
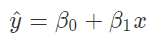
해당 직선에 $\beta_0(기울기)$와 $\beta_1(회귀 계수)$의 의미를 파악해보자.
종속변수: price, 독립변수: sqft_living
import numpy as np
print(f'y = {model_sqft.coef_[0][0]:.02f}x - {np.abs(model_sqft.intercept_[0]):.02f}')
#output
y = 280.62x - 43580.74
독립변수(sqft_living)와 종속변수(price)간의 회귀직선에서 회귀계수와 y절편을 확인할 수 있다. 회귀계수를 통해 알 수 있는 내용은 1 sqft당 280$가 증가한다고 해석할 수 있다. 종속변수와 독립변수가 서로 비례 관계임을 확인할 수 있다.
2. Oridinary Least Square
[OLS 구하는 공식]
<img src=’/assets/ols.PNG’ width = >
OLS란 선형회귀모델을 통해 구한 회귀직선(예측값)과 실제값 사이의 거리(에러 or 잔차)의 제곱의 합이 최소가 되는 것을 찾는 방법이다.
머신러닝에서는 주어진 데이터를 이용해 오차 제곱의 합이 최소가 되는 모델을 찾기 위해 학습을 진행하게 되는 것이다.
OLS 방법을 이용해 학습을 진행하고, 그 결과 얻어진 모델을 이용해 주어져 있지 않는 데이터를 보간하여 값을 예측하게 되는 것이다.
- 보간(Interpolate)란?
- 기존 데이터 범위 사이에 없는 범위를 예측하는 것을 말한다.
2-1. RSS & SSE & Cost Function?
-
OLS에 대해 공부하다보면 RSS, SSE, Cost Function이란 용어를 확인할 수 있을 것이다. 각 용어가 무엇을 의미하는지 살펴보겠다.
-
RSS(Residual Sum of Squares) & SSE(Sum of Square Error)
RSS는 말 그대로 잔차 제곱의 합을 의미하고 SSE는 에러 제곱의 합을 의미한다. 잔차와 에러 둘다 머신러닝에서 의미하는 바는 같기 때문에 두 용어의 의미는 동일하다고 생각하면 된다. -
Cost Function Cost Function은 회귀모델의 비용함수인데, 여기서 비용함수가 결국 RSS & SSE를 의미한다. 결국 3 용어가 가지는 의미가 모두 비슷하다는 것을 확인할 수 있다.
-
-
머신러닝에서의 학습은 사용하고자 하는 모델의 비용함수를 최소화하는 모델을 찾는 과정을 말한다.
3. 기준모델(Baseline Model)
이렇게 예측 모델을 구체적으로 만들기 전에 가장 간단하면서도 직관적이면서 최소한의 성능을 나타내는 기준이 되는 모델을 기준모델 이라고 합니다. 즉 나중에 우리가 학습할 모델과 간단하게 비교할 목적으로 만드는 모델을 기준모델 이라고 한다.여기서는 평균값을 기준으로 사용해서 평균기준모델이라고 말할 수 있겠습니다.
참고로 문제별로 기준모델은 보통 다음과 같이 설정합니다.
- 분류문제: 타겟의 최빈 클래스
- 회귀문제: 타겟의 평균값
- 시계열회귀문제: 이전 타임스탬프의 값
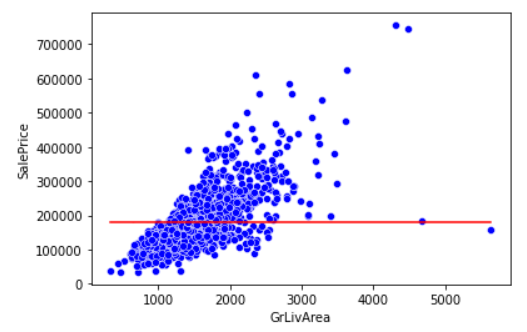
미국 시애틀 king county의 주택 판매 가격 데이터 셋을 이용해 기준모델을 구해보겠습니다.
predict = df['SalePrice'].mean() # 예측한 주택 가격 - 전체 주택 가격의 평균
errors = predict - df['SalePrice']
#독립변수 - GrLiveArea, 종속변수 - SalePrice
x = df['GrLivArea']
y = df['SalePrice']
predict = df['SalePrice'].mean()
errors = predict - df['SalePrice']
mean_absolute_error = errors.abs().mean()
sns.lineplot(x=x, y=predict, color='red') ## 기준모델
sns.scatterplot(x=x, y=y, color='blue');
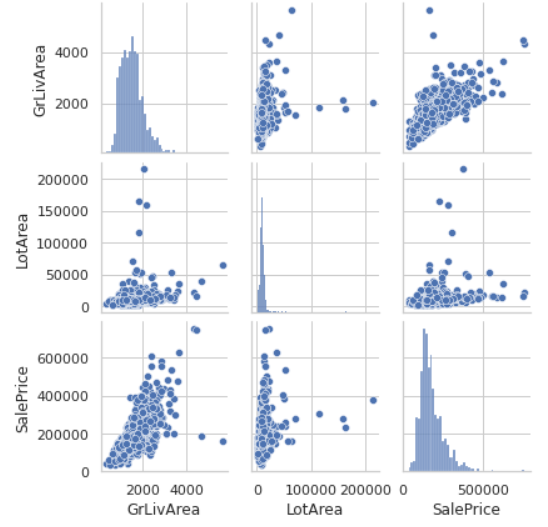
GrLiveArea 특성 말고 다른 특성과는 어떠한 관계가 있는지 확인
sns.set(style='whitegrid', context='notebook')
cols = ['GrLivArea', 'LotArea','SalePrice']
sns.pairplot(df[cols], height=2);
4. 머신러닝?
만약, 머신러닝 자체가 이해가 잘 가지 않는다면 아래 그림을 보면 이해하는데 도움이 될 것입니다.
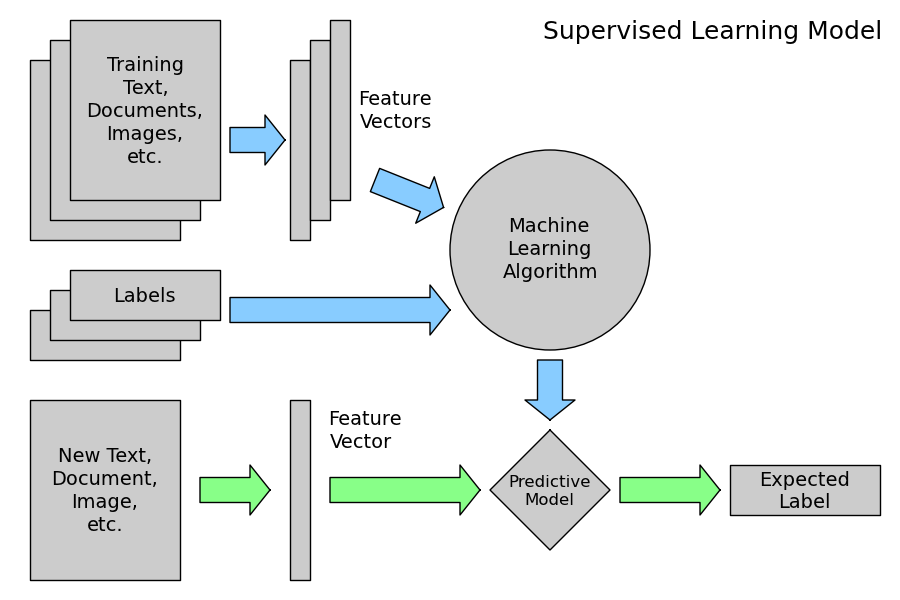
[process]
- train dataset을 feature, target data로 나눈다.
- 나눈 train data를 이용해 우리가 사용할 머신러닝 모델을 학습시킨다.
- 학습된 모델을 이용해 test data의 feature data로 우리가 예측하고자 하는 target data를 예측한다.
- 결과를 확인한다.
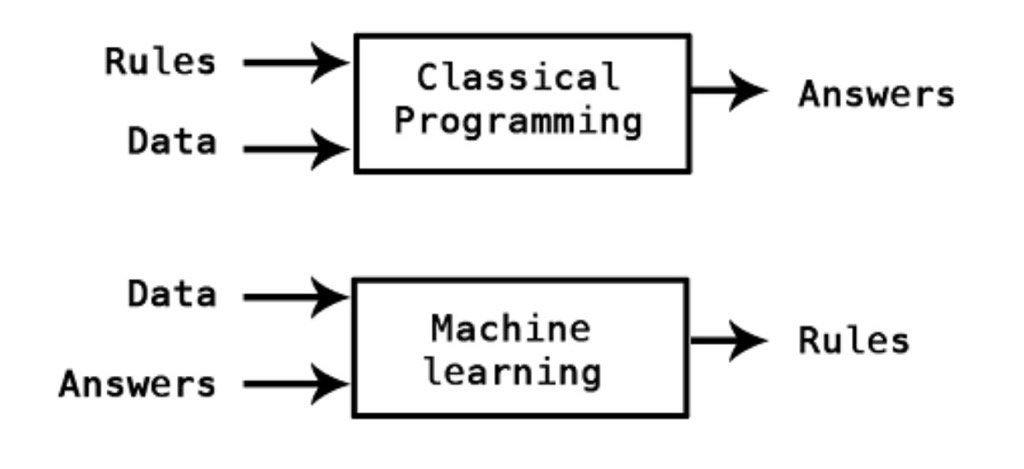
4-1. 머신러닝의 새로운 패러다임
기존의 프로그래밍은 프로그래머가 넣어주는 규칙과 데이터를 통해 원하는 결과를 구했습니다. 하지만 머신러닝은 데이터와 답을 넣어주고 규칙을 구하는 새로운 패러다임을 가지고 왔습니다.