[Python] dataframe

Python - Useful Dataframe Method
1. data indexing (iloc)
#읽어온 데이터프레임에서 column 특정 범위만 가지고 온다.
data1 = pd.read_csv(url1).iloc[:,1:]
#또 다른 방법
data1 = data1.drop(data1.columns[0],axis=1)
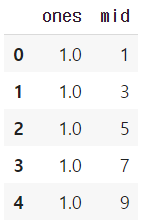
2. Add index’s name
df.rename_axis('추가하고 싶은 명')
df.rename_axis('index')
# output
3. 데이터 프레임 내 특정 컬럼의 특정 데이터 값만을 뽑고 싶은 경우
#loc을 사용해 country 컬럼에서 united states와 china의 특정 값만을 추출
df_join = join_data.loc[(join_data['country']=='United States') | (join_data['country']=='China')]
#concat을 사용해 country 컬럼에서 united states와 china의 특정 값만을 추출
usa_china_data = pd.concat([join_data[join_data['country'] == 'United States'],join_data[join_data['country'] == 'China']],axis=0)
4. dataframe 정렬 방법
#인덱스를 기준으로 오름차순으로 정렬된다.
df = df.sort_index()
df = df.sort_index(ascending = False) #내림차순으로 정렬
#특정 컬럼을 기준으로 정렬
df = df.sort_values()
df = df.sort_values(ascending = False)#내림차순으로 정렬
5. df.dropna(how=’any’ or ‘all’)
df.dropna(how='any')
- 만약 na가 존재하면, axis=0 or 1에 따라 해당 행이나 열 삭제!
df.dropna(how='all')
- 만약 지정된 행이나 열(axis=0 or 1)에 모든 값이 na일때 그 행 or 열 삭제!
6. iloc & loc을 사용해야 하는 이유
#아래와 같이 인덱싱을 하게 되면 경고 메세지가 뜨는데,
join_data[join_data['time']==2019][join_data['country']=='South Korea']['PPP']
#ouput
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:2: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
#이러한 경고 메세지를 안 받기 위해서는 iloc이나 loc을 사용해서 인덱싱을 해줘야 한다.
7. 데이터프레임 컬럼 인덱싱
df[['컬럼명1','컬럼명2']]
#output
해당 컬럼명만을 포함하는 데이터프레임을 인덱싱한다.
8. dataframe내의 데이터로 공분산, 상관계수 구하기
#공분산
df.cov()
#output:
v w
v 1363.7 71.7
w 71.7 149.7
#상관계수
df.corr()
#output:
v w
v 1.00000 0.15869
w 0.15869 1.00000
9. 데이터프레임 정렬
#기준 데이터프레임
df = df.loc[:,['Name','Genre']].head(5)
#output:
Name Genre
6774 Imagine: Makeup Artist Simulation
5204 Brothers Conflict: Precious Baby Action
9921 Phantasy Star Online 2 Episode 4: Deluxe Package Role-Playing
14921 Phantasy Star Online 2 Episode 4: Deluxe Package Role-Playing
14191 Lego Star Wars: The Force Awakens Action
1. 컬럼 값을 기준으로 정렬
df.sort_values('Genre',ascending = TRUE OR FALSE)
#ascending : 오름차순, 내림차순 설정 파라미터
#output:
Name Genre
15785 Legend of Kay Action
6436 Harry Potter and the Deathly Hallows - Part 1 Action
503 Rudolph the Red-Nosed Reindeer Action
3346 Harry Potter and the Chamber of Secrets Action
8355 Darksiders Action
2. 특정 컬럼을 기준으로 시리즈를 정렬
df['Genre'].sort_values()
#output:
15785 Action
6436 Action
503 Action
3346 Action
8355 Action
Name: Genre, dtype: object
3. 여러 컬럼을 기준으로 정렬
df.sort_values(['Name','Genre'],ascending = False) # 내림차순
#output:
Name Genre
213 ¡Shin Chan Flipa en colores! Platform
14716 uDraw Studio: Instant Artist Misc
3009 uDraw Studio: Instant Artist Misc
13679 uDraw Studio Misc
3431 thinkSMART: Chess for Kids Misc
10. 데이터프레임 복수 조건 설정
1. and
df[(df['조건 컬럼1'] > 10) & (df['조건 컬럼2'] < 10)]
#output: 해당 조건 컬럼을 만족하는 데이터프레임 추출.
2. or
df[(df['조건 컬럼1'] > 10) | (df['조건 컬럼2'] < 10)]
ps) 연산자 우선 순위
NOT(~) > AND(&) > OR(|)
11. 데이터프레임 합치기
#열을 기준으로 concat
pd.concat(['데이터프레임1','데이터프레임2'],axis=1)
#행을 기준으로 concat
pd.concat(['데이터프레임1','데이터프레임2'],axis=0) #axis = 0은 default 값
#concat parameter keys
pd.concat(['데이터프레임1','데이터프레임2'],keys = ['key명1','key명2'])
#output:
12. np.where
- 인덱스 찾기
numpy.where(numpy배열 == 찾을 값) or numpy.where(pd.Series형태 == 찾을 값)
np.where(np.array([1,2,3])==3)[0]
#output: array([2])
- 데이터 결합
s1 = pd.Series([np.nan,4,4,7,9])
s2 = pd.Series([1,np.nan,3,np.nan,np.nan])
s3 = pd.Series([10,3,4,5,np.nan])
print(s1)
#output:
0 NaN
1 4.0
2 4.0
3 7.0
4 9.0
dtype: float64
np.where(pd.isnull(s1),s3,s1)
#output: array([10., 4., 4., 7., 9.])
#s1내부에 null 값인 인덱스에 해당하는 s3의 값과 s1을 결합. 즉, 10.0은 s3의 해당 인덱스의 원소이다. 나머지 원소는 s1의 내부 원소
13. one hot encoding
# one hot encoding
select_column = ['genre']
def one_hot_encoding(train_data):
for cate in select_column:
prefix=cate
one_hot_encoding = pd.get_dummies(train_data[cate],prefix=prefix)
train_data = pd.concat([pd.DataFrame(train_data),one_hot_encoding],axis = 1)
train_data = train_data.drop(cate,axis=1)
return train_data.copy()
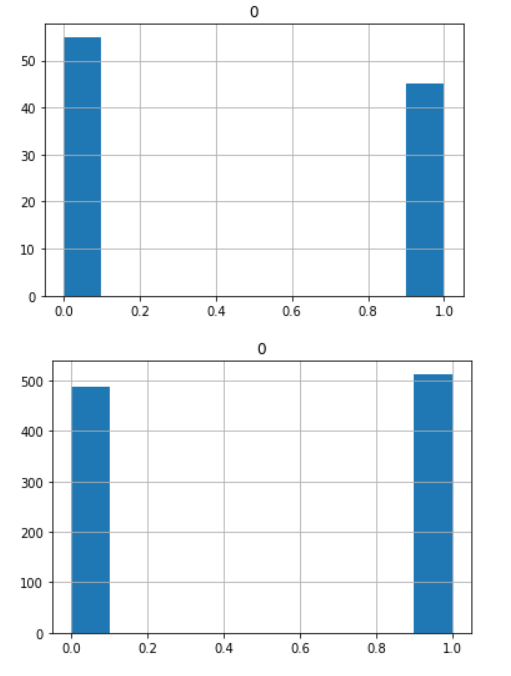
14. pd.DataFrame().hist()
pd.DataFrame(np.random.binomial(n = 1, p = 0.5, size = 100)).hist();
pd.DataFrame(np.random.binomial(n = 1, p = 0.5, size = 1000)).hist();