[Python] scikit-learn Library
개요

scikit-learn은 머신러닝 모델을 만드는데 가장 많이 사용하는 라이브러리이다. sckit-learn에는 수많은 머신러닝 모델이 구현되어 있고 모든 프로세스가 거의 다 비슷하다.
해당 라이브러리를 이용해 단순 선형회귀모델을 만들어보겠습니다.
우리가 이용할 데이터 셋
import pandas as pd
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/house-prices/house_prices_train.csv')
df_t = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/house-prices/house_prices_test.csv')
train dataset
test dataset

1. 사전 준비
scikit-learn을 사용하기 위해서는
- 데이터 셋을 특성 데이터(feature matrix)와 타겟 데이터(label vetor)로 나눠 줘야 한다.
- 특성행렬은 주로 X로 표현하고 보통 2차원 행렬이다. 주로 Numpy 행렬이나 Pandas 데이터프레임으로 표현한다.
- 타겟배열은 주로 y로 표현하고 보통 1차원 형태의 벡터이다. 주로 Numpy 배열이나 Pandas Series로 표현한다.
2. 모델 구현
선형회귀모델에서 가장 단순한 형태의 모델입니다.
# LinearRegression import
from sklearn.linear_model import LinearRegression
# Regression instance
model = LinearRegression()
# X(특성 변수), y(타겟 변수) 생성
feature = ['GrLivArea']
target = 'SalePrice'
X_train = df[feature] #X가 대문자인 이유는 행렬임을 표시
y_train = df[target] #y가 소문자인 이유는 벡터임을 표시
# model train
model.fit(X_train,y_train) # fit() 함수 사용
# 임의의 새로운 데이터를 이용해 예측
X_test = [[4000]]
y_pred = model.predict(X_test) # predict() 함수 사용
print(f'{X_test[0][0]} sqft GrLivArea를 가지는 주택의 예상 가격은 ${int(y_pred)} 입니다.')
#output
4000 sqft GrLivArea를 가지는 주택의 예상 가격은 $447090 입니다.
# test data 전체로 예측
# X_test = [[x] for x in df_t['GrLivArea']] #행렬값으로 변환
X_test = df_t[['GrLivArea']]
y_pred = model.predict(X_test)
print(y_pred)
array([114557.82748987, 160945.27292207, 193084.38061182, ...,
149696.58523066, 122485.47405334, 232829.74378814])
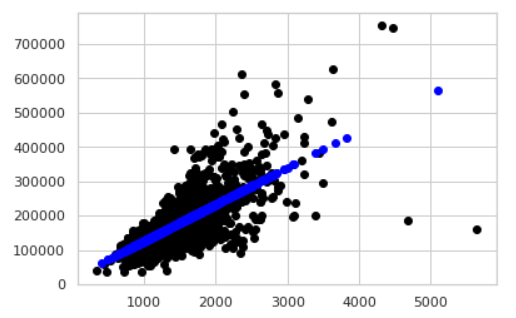
# train data scatterplot
import matplotlib.pyplot as plt
plt.scatter(X_train,y_train,color = 'black', linewidth = 1)
# test data scatterplot
plt.scatter(X_test,y_pred,color = 'blue', linewidth = 1)